
یادگیری عمیق یکی از تنها متدهایی است که با آن میتوان بر چالش های استخراج ویژگی غلبه کرد؛ به این دلیل که مدل های یادگیری عمیق قادر به یادگیری تمرکز روی ویژگی های مناسب بوده و به راهنمایی کمی از سوی برنامه نویس نیازمند هستند. اساسا یادگیری عمیق از نحوه ی عملکرد مغز تقلید میکند، به عبارت دیگر از تجربه ها یاد میگیرد. همانطور که میدانید مغز ما از میلیاردها عصب تشکیل شده که به ما امکان انجام کارهای خارق العاده ای را میدهد. حتی مغز یک بچه یک ساله نیز قادر به حل مشکلات پیچیده ای است که حل آنها برای سوپرکامپیوترها هم بسیار دشوار است. به عنوان مثال:
- تشخیص چهره والدین خود و همچنین اشیاء مختلف.
- تشخیص صداهای مختلف از یکدیگر و شناسایی افراد بر اساس صدای آنها.
- فهم حس و حال چهره سایر افراد و بسیاری از کارهای دیگر.
در حقیقت مغز ما در طول سالیان مختلف و به صورت نیمه خودآگاه خود را برای انجام چنین چیزهایی آموزش داده است. در حال حاضر، سوالی که پیش می آید این است که یادگیری عمیق چگونه از عملکرد مغز تقلید میکند؟ یادگیری عمیق از مفهوم عصب های مصنوعی که عملکردی مشابه عصب های های بیولوژیکی مغز انسانها دارند استفاده میکنند. بنابراین میتوان گفت که یادگیری عمیق زیرمجموعه ای از یادگیری ماشین است که خود به الگوریتم های الهام گرفته از ساختار و عملکرد مغز که شبکه های عصبی مصنوعی نامیده میشوند وابسته است.
حال برای روشن شدن این موضوع به مثال زیر نگاهی بیاندازید. ساختن سیستمی را متصور شوید که قادر به تشخیص چهره ی چندین فرد مختلف در یک تصویر باشد. در صورتی که این مشکل را به عنوان یک مشکل یادگیری ماشین معمولی حل کنیم، ویژگی های چهره ای چون چشم، دماغ، گوش ها و غیره را تعریف خواهیم کرد و سپس سیستم تشخیص خواهد داد که کدام یک از ویژگی ها برای کدام یک از افراد حائزاهمیت است.
در حال حاضر یادگیری عمیق این کار را یک مرحله پیشتر برده است. یادگیری عمیق به صورت خودکار ویژگی های حائزاهمیت برای طبقه بندی را با کمک شبکه های عصبی عمیق خود پیدا میکند، این در حالی است که در یادگیری ماشین، این ویژگی ها باید به صورت دستی تعریف شوند.
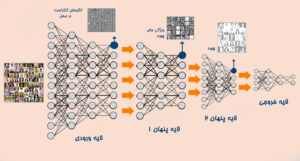
تشخیص چهره با استفاده از شبکه های عمیق
همانطور که در تصویر بالا نشان داده شده است، یادگیری عمیق به شکل زیر عمل میکند: در پایین ترین سطح، شبکه روی الگوهای کنتراست داخلی به عنوان موضوعی مهم تمرکز میکند. لایه بعدی قادر به استفاده از آن الگوهای کنتراست داخلی برای تمرکز روی چیزهایی که مشابه چشم ها، دماغ ها و دهان ها است. در آخر، لایه نهایی قادر به بکارگیری آن ویژگی های چهره در قالب های چهره است. یک شبکه عصبی عمیق قادر به ساخت ویژگی های پیچیده و پیچیده تری در هر یک از لایه های بعدی خود است.
آیا تا به حال این سوال برای شما پیش آمده است که فیسبوک چگونه به صورت خودکار تمامی افراد حاضر در یک تصویر آپلود شده توسط شما را لیبل و برچسب گذاری میکند؟ فیسبوک همچون مثال قبل که پیشتر ذکر شد از یادگیری عمیق استفاده میکند. قابلیت های یادگیری عمیق و اینکه چگونه در مواردی که از اثر یک سری از ویژگی ها بیخبر بوده ایم یادگیری عمیق توانسته از لحاظ عملکرد از یادگیری ماشین سبقت بگیرد از جمله مواردی هستنند که شاید تا به اکنون متوجه آنها شده باشید.
در نتیجه شبکه های عمیق میتوانند با بهره جویی از مجموع داده های شامل داده های ورودی فاقد برچسب گذاری مناسب، از پس نقاط ضعف یادگیری ماشین برآیند.

شبکه عصبی چیست؟
همانطور که از نام آن برمی آید، یادگیری عمیق زیرمجموعه ای از یادگیری ماشین است. یادگیری عمیق برای پرداختن به مشکلات یادگیری ماشین، بیشتر درگیر استفاده از شبکه های عصبی مصنوعی عمیق (الگوریتم ها/مدل های محاسباتی که تا حدودی از مغز انسان الهام گرفته اند) شده است.
حال سوالی که ذهن افراد را درگیر میکند این است که اصلا شبکه عصبی چیست و چه کاری در یادگیری عمیق انجام میدهد؟ به مقایسه زیر توجه کنید: شبکه ی عصبی را همچون یک سری درب که پشت سر یکدیگر قرار گرفته اند در نظر بگیرید و خود را به عنوان یک “ورودی” به شبکه عصبی موجود ببینید. هر زمان که یکی از این درب ها را باز میکنید، تبدیل به یک فرد جدید میشوید (به عبارت دیگر، به نحوی یک تغییر در شما اتفاق می افتد). و زمانی که به آخرین درب میرسید، به یک فرد کاملا متفاوت تبدیل شده اید. هنگامی که از درب آخر خارج میشوید، به “خروجی” شبکه عصبی تبدیل میشوید. در این مورد، هر یک از درب ها نشان دهنده ی یک لایه هستند. بنابراین یک شبکه عصبی مجموعه ای از لایه هایی است که به نحوی ورودی موردنظر را تغییر داده و به ایجاد خروجی پرداخته است.
هر یک از لایه های موجود در شبکه ی عصبی شامل “وزن ها” و “جهت گیری ها”ی خاص خود هستند – این موارد تنها اعدادی هستند که بر ورودی افزوده میشوند. عملکرد کلی شبکه های عصبی به این شکل است که تعدادی ورودی دریافت کرده (معمولا مجموعه ای از اعداد که نمایش دهنده ی چیزی هستند، به عنوان مثال، مقادیر قرمز-سبز-آبی پیکسل ها در یک تصویر)، با استفاده از وزن ها و جهت گیری های لایه های خود یک سری تغییرات محاسبه شده انجام داده و در نهایت یک خروجی را بیرون میدهد. در صورتی که قبلا یک سری کلاس جبر گذرانیده باشید میتوانید به این ورودی ها، خروجی ها و وزن ها به عنوان یک سری ماتریس نگاه کنید. ماتریس ورودی توسط یک سری ماتریس تغییر داده شده (به عبارت دیگر، ماتریس های وزن و جهت گیری های لایه مربوطه) و به خروجی شما تبدیل میشود. البته ذکر این نکته حائز اهمیت است که توصیف ارائه شده توضیحی بسیار ساده از نحوه عملکرد یک شبکه عصبی بوده و تنها برای فهم بهتر آن مطرح شده است.
یک شبکه عصبی عمیق تنها یک شبکه عصبی با تعداد لایه های زیاد است (با قرار دادن لایه ها روی یکدیگر، شبکه ی عصبی شما شروع به “عمیق تر” شدن میکند. ایده ی اولیه یادگیری عمیق، استفاده از شبکه های عصبی به همراه چندین لایه مختلف بوده است).

حال سوالی که مطرح میشود این است: شبکه ی عصبی چگونه یاد میگیرد؟ از طریق “پس انتشار“. این واژه به روش معمول برای آموزش یک شبکه عصبی گفته میشود که در آن خروجی اولیه سیستم با خروجی دلخواه مقایسه شده و تا جایی که تفاوت بین آنها به حداقل برسد، سیستم مربوطه تنظیم میشود. همانطور که قبلا گفته شد شبکه های عصبی از لایه هایی تشکیل شده اند که وزن ها و جهت گیری های خاص خود (که تنها مجموعه ای از اعدادند) را شامل میشوند. در جریان فاز آموزش، شبکه های عصبی در جهت یافتن وزن ها/جهت گیری های درستی تلاش میکنند که قادر به ارائه ی دقیقترین خروجی ها باشند. این کار با استفاده از روشی تحت عنوان پس انتشار انجام میشود. پیش از آموزش دادن یک شبکه عصبی، وزن ها/ جهت گیری ها یا به صورت رندوم و یا با توجه به یک مدل آموزش دیده شده ی قبلی آماده سازی میشوند. در هر دو صورت هنگامی که آموزش صورت میگیرد، شبکه ی عصبی آن وزن ها و جهت گیری ها را با توجه به آنچه که “یاد میگیرد” تغییر میدهد. هنگامی که یک شبکه ی عصبی میسازیم، باید روی چیزی به عنوان تابع هزینه تصمیم گیری (به عبارت دیگر، انتخاب یا طراحی) کنیم. تابع هزینه اساسا به نوعی تابع ریاضی گفته میشود که خروجی را از یک شبکه ی عصبی (برای یک ورودی معین) و داده ی عینی (به عبارت دیگر، خروجی مورد انتظار از شبکه ی عصبی برای ورودی مشخص شده) دریافت و میزان غلط/بد بودن نتیجه حاصل از شبکه های عصبی را محاسبه میکند.
با استفاده از تکنیک های بهینه سازی همچون گرادیان کاهشی، کامپیوتر شما چگونگی تغییر وزن ها و جهت گیری ها را یاد میگیرد تا بدین شکل تابع هزینه را به حداقل برساند. اما گرادیان کاهشی به چه معناست؟ گرادیان کاهشی یک الگوریتم بهینهسازی مرتبه اول الگوریتم تکرار شونده است. برای یافتن کمینه محلی یک تابع با استفاده از این الگوریتم، گامهایی متناسب با منفی گرادیان (یا گرادیان تخمینی) تابع در محل فعلی برداشته خواهد شد. اگر در استفاده از این الگوریتم، گامهایی متناسب با جهت مثبت گرادیان برداشته شود، به بیشینه محلی تابع نزدیک میشویم که به این فرایند گرادیان افزایشی گفته میشود. سیستم مربوطه با یاد گرفتن با توجه به داده های بیشتر و بیشتر به انجام این کار ادامه میدهد (خروجی را از شبکه ی عصبی دریافت، هزینه را محاسبه و برای تغییر وزن ها کار “پس انتشار” را که پیشتر توضیح داده شد انجام میدهد). به مرور زمان، وزن ها و جهت گیری های سیستم با توجه به داده ها تنظیم میشوند و در آخر شبکه ای عصبی با دقت خروجی بالا در دست خواهید داشت. به یاد داشته باشید که کارایی عملی یا دقت یک شبکه عصبی تا حد زیادی به داده های استفاده شده برای آموزش آن وابسته است: بنابراین این موضوع بسیار حائزاهمیت است که بانک اطلاعاتی مجموع داده های شما به درستی ساخته یا انتخاب شده باشد. بدون وجود داده ی خوب (و میزان داده ی خوب) کار آموزش یک شبکه ی عصبی دقیق بسیار دشوار تمام خواهد شد.
به علاوه، تابع هزینه اساسا میزان عدم دقت شبکه ی عصبی مربوطه را اندازه گیری میکند؛ با به حداقل رساندن تابع هزینه به وسیله تغییر وزن ها/جهت گیری ها، شبکه ی عصبی شما از لحاظ عددی بسیار دقیقتر خواهد شد. با این حال، دقت شبکه عصبی وابسته به داده ای است که بر اساس آن آموزش داده میشود؛ بنابراین یک هزینه پایین ضرورتا به معنای یک شبکه ی عصبی آموزش دیده به قدر کافی نیست.
موارد کاربرد یادگیری عمیق
1. تشخیص صدا

شاید اسم سیری به گوش شما خورده باشد؛ سیری یک راهنمای هوشمند صوتی در محصولات شرکت اپل است. همچون سایر غول های بازار، شرکت اپل نیز روی یادگیری عمیق سرمایه گذاری کرده تا بدین شکل بتواند خدمات خود را با کیفیت بیشتری در مقایسه با گذشته ارائه کند. در زمینه تشخیص صدا و راهنمای هوشمند صدایی چون سیری، افراد میتوانند با استفاده از شبکه های عصبی عمیق مدلهای صوتی دقیقتری را بسازند. در حال حاضر این زمینه یکی از فعالترین زمینه ها برای بکارگیری یادگیری عمیق است. به بیان ساده، با کمک این تکنولوژی شما قادر به ساخت سیستمی هستید که میتواند ویژگی های جدید یاد بگیرد و یا با توجه به شما خود را تغییر دهد. بنابراین با پیش بینی تمام احتمالات از قبل، به نحو بهتری راهنمایی در اختیار شما قرار میگیرد.
2. ترجمه ماشینی خودکار
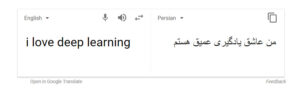
همه ما میدانیم که گوگل قادر به ترجمه فوری بین 100 زبان مختلف بوده و سرعت آن به قدری است که همچون یک معجزه به نظر می آید. تکنولوژی پشت گوگل ترنزلیت ترجمه ماشینی نامیده میشود و برای افرادی که به خاطر تفاوت زبانشان قادر به برقراری ارتباط با یکدیگر نبوده اند همچون یک نجات دهنده عمل کرده است. حال ممکن است که این سوال برایتان پیش آید: « این ویژگی برای مدت های زیادی است که وجود دارد، پس دیگر چه چیز جدیدی برای ارائه میتواند داشته باشد؟» در طول چند سال گذشته، گوگل با کمک یادگیری عمیق رویکرد موجود نسبت به ترجمه ماشینی را در گوگل ترنزلیت خود به کلی دگرگون کرد. در حقیقت پژوهشگران یادگیری عمیقی که تقریبا چیزی در مورد ترجمه ماشینی نمیدانند، با ارائه و بکارگیری راهکارهای یادگیری ماشینی ساده توانسته اند بهترین و پیشرفته ترین سیستم های ترجمه زبانی در جهان را شکست دهند. ترجمه متون در این سیستم ها بدون نیاز به پیش پردازش توالی متون انجام میگیرد و به الگوریتم ها اجازه میدهد که ارتباط بین کلمات و معادل آنها را در زبان جدید یاد بگیرند. شبکه های فشرده ای از شبکه های عصبی متناوب و بزرگ برای انجام این ترجمه لازم است.
3. ترجمه بصری فوری

همانطور که میدانید یادگیری عمیق برای مواردی چون تشخیص تصاویری که دارای حروف اند و یا در مکانهایی که حروف در یک صحنه حضور دارند استفاده میشود. به محض شناسایی، این تصاویر را میتوان به متن تبدیل و ترجمه کرد و تصاویری با متن ترجمه شده از نو ایجاد نمود. حال شرایطی را تصور کنید که به کشور دیگری که زبان آن را نمیدانید سفر کرده اید. هیچ جای نگرانی نیست! با استفاده از اپلیکیشن های مختلفی چون گوگل ترنزلیت میتوانید برای خواندن علامت ها و یا تابلوهای خرید نوشته شده به زبان دیگر به سرعت ترجمه بصری انجام دهید.
4. خودروهای بدون راننده و اتوماتیک

شرکت گوگل در تلاش است که با استفاده از یادگیری عمیق مقدمات ساخت خودروهای بدون راننده خود ﴿معروف به WAYMO﴾ را فراهم و به سطح جدیدی از تکامل برساند. بنابراین به جای استفاده از الگوریتم های کدگذاری شده به صورت دستی، افراد میتوانند سیستم را طوری برنامه ریزی کنند که با استفاده از داده های ارائه شده توسط سنسورهای مختلف به خودی خود همه چیز را یاد بگیرند. در حال حاضر یادگیری عمیق به عنوان بهترین رویکرد نسبت به اکثر عملیات های ادراکی و همچنین بسیاری از عملیات های کنترلی سطح-پایین تلقی میگردد. از این رو در حال حاضر حتی افرادی که رانندگی بلد نبوده و یا ناتوان از رانندگی هستند نیز میتوانند بدون نیاز به سایر افراد وسیله نقلیه خود را برانند.
موارد ذکر شده تنها برخی از موارد مطرح استفاده از یادگیری عمیق بوده است که در آنها از این تکنولوژی به صورت گسترده استفاده شده و نتایج مطلوبی به دست آمده است. در بسیاری از حوزه هایی که جای بررسی و تامل دارند، یادگیری عمیق کاربری های دیگری نیز دارد.
برگرفته از edureka و towardsdatascience