

به دلیل استفاده ی گسترده از مانیتورینگ با وضوح بالا، در یک بازه ی زمانی کوتاه میزان داده های موردنیاز برای نظارت امنیتی به شکل قابل توجهی افزایش پیدا کرده است. جمع آوری کارآمد، تجزیه و تحلیل و بکارگیری داده ها و استفاده هوشمندانه از آنها بیشتر از هر زمان دیگری در این صنعت به موضوعی جدی تبدیل شده است. بنابراین ارتقاء سطح هوشمندی ویدئویی، هدفی ناگزیر و همه گیر در این صنعت به نظر میرسد. کاربران امنیتی امیدوارند که سرمایه گذاری آنها روی محصولات جدید، مزایایی فراتر از دنباله روی و جستجوی ساده علایق افراد و جمع آوری شواهد پس از یک رخداد امنیتی برای آنها به ارمغان آورد. به جای آن نیاز به یافتن راه های چه بسا کارآمدتر که به نظارت اجازه ی گذار از جستجو پس از وقوع رخداد به هشدارهایی حین وقوع رخداد و یا حتی هشدارهایی پیش از وقوع رخداد به شدت احساس میشود. برای برآورده سازی این نیازها، تکنولوژی های جدیدی لازم است. نظارت ویدئویی هوشمند برای سالهای زیادی در دسترس بوده است. با این حال، نتایج بکارگیری آن چندان ایده آل واقع نشده است. ظهور یادگیری عمیق، امکان تحقق این نیازها را برآورده ساخته است.
عدم کفایت الگوریتم های هوشمند قدیمی
نظارت ویدئویی هوشمند قدیمی دارای الزامات بسیار دقیقی برای پس زمینه ی یک صحنه است. دقت شناسایی و تجزیه و تحلیل هوشمند در سناریوهای مشابه به صورت یکنواخت باقی نمی ماند.
ویژگی های موجود در الگوریتم های هوشمند قدیمی توسط انسانها طراحی شده اند و همیشه به شدت فردی بوده اند. ذات این سیستم های به گونه ای است که ویژگی های غیر شهودی تر (ویژگی هایی که فهم و توصیف آنها برای انسانها دشوارند) در آنها نادیده گرفته میشوند. در فرآیند یادگیری طبقه بندی، با بالا رفتن تعداد دسته های موجود برای طبقه بندی، سطح دشواری نیز بالا میرود.
الگوریتم های هوشمند قدیمی معمولا از مدلهای یادگیری سطحی برای حل و فصل شرایطی با میزان داده های بزرگ در طبقه بندی های پیچیده استفاده میکنند. نتایج این تجزیه و تحلیل با شرایط ایده آل بسیار فاصله دارد. از سوی دیگر، این نتایج مستقیما وسعت و عمق کاربری های هوشمند و پیشرفت بیشتر آنها را محدود میسازد. از این رو برای صنعت امنیت، نیاز به افزایش “عمق” هوشمندی در کلان داده ها در حال پدیدار شدن است.

مزایای یادگیری عمیق و الگوریتم های آن
الگوریتم های هوشمند قدیمی توسط انسانها طراحی شده اند. این سیستم ها چه در صورتی که خوب طراحی شده باشند و چه برعکس، تا حد زیادی وابسته به تجربه و حتی شانس هستند و این فرآیند نیازمند زمان بسیار زیادی است. بنابراین آیا میتوان با این ماشین ها کاری کرد که به صورت خودکار برخی از این ویژگی ها را یاد بگیرند؟ بله! در واقع این کار هدف هوش مصنوعی (AI﴾ است.
طرح تکنولوژی یادگیری عمیق از شبکه های عصبی مغز یک انسان الهام گرفته شده است. به مغز ما انسانها میتوان به چشم یک مدل یادگیری عمیق پیچیده نگاه کرد. شبکه های عصبی مغز متشکل از میلیاردها عصب به یکدیگر متصل هستند؛ یادگیری عمیق این ساختار را شبیه سازی میکند. این شبکه های چندلایه ای قادر به جمع آوری اطلاعات و انجام فعالیت های متناظر واز قابلیت تشخیص و بازآفرینی سوژه برخوردار هستند.
یادگیری عمیق به صورت ذاتی با الگوریتم های دیگر متفاوت است. نحوه ی حل و برطرف سازی عدم کفایت الگوریتم های سنتی توسط یادگیری عمیق در جنبه های ذیل گنجانده شده است.
نخست، از “سطحی” به “عمیق”
مدل الگوریتمی یادگیری عمیق از ساختار به مراتب عمیق تری نسبت به دو ساختار سه لایه ای الگوریتم های قدیمی برخوردار است. در برخی از موارد، تعداد لایه ها به بیش از یکصد میرسد که این موضوع یادگیری عمیق را قادر به پردازش حجم زیادی از داده در طبقه بندی های پیچیده میسازد. یادگیری عمیق بسیار مشابه فرآیند یادگیری انسان عمل میکند و دارای فرآیند تشخیص ویژگی لایه لایه است. یادگیری عمیق به ما کمک میکند تا فهم جزئی (سطحی) به یک تشخیص کلی (عمیق) تبدیل شده و بدین شکل سوژه موردنظر شناسایی شود.
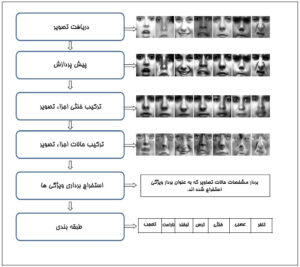
دوم، از “ویژگی های مصنوعی” به “یادگیری ویژگی”
یادگیری عمیق نیازی به مداخله دستی ندارد، ولی در عوض برای استخراج ویژگی ها وابسته به یک کامپیوتر است. بدین شکل یادگیری عمیق میتواند بیشترین تعداد ویژگی های ممکن را از سوژه موردنظر استخراج کند؛ ویژگی های غیرشهودی که برای توصیف دشوار یا غیرممکن هستند از جمله این ویژگی ها محسوب میشوند. هر چه تعداد ویژگی ها بیشتر باشد، امر شناسایی و تشخیص دقیقتر خواهد بود.
فاکتورهای اصلی یادگیری عمیق
به صورت کلی سه دلیل عمده برای شهرت یافتن یادگیری عمیق در سالهای اخیر (چرا زودتر از آن این اتفاق نیافتاده است!) وجود دارد: مقیاس داده های موردنیاز، قدرت محاسبه و ساختار شبکه.
پیشرفتهای صورت گرفته در عملکرد الگوریتم های داده-محور در یک بازه ی زمانی بسیار کوتاه باعث تسریع نفوذ یادگیری عمیق در کاربری های هوشمند مختلف شده است. مخصوصا که با افزایش در مقیاس داده ها، عملکرد الگوریتمی نیز بهبود یافته است. از این رو تجربه ی کاربر بهبود یافته و کاربران بیشتری درگیر این موضوع شده اند که این کار خود باعث تسهیل بیشتر در مقیاس بزرگتری از داده ها شده است.
پلتفرم های سخت افزاری با عملکرد بالا باعث فعالسازی قدرت محاسباتی بیشتر میشوند. مدل یادگیری عمیق نیازمند تعداد نمونه های زیادی است که این موضوع انجام حجم زیادی از محاسبات را اجتناب ناپذیر میسازد. پیشرفت سریع واحدهای پردازش گرافیکی ﴿GPU﴾، سوپرکامپیوترها، محاسبات ابری و سایر پلتفرم های سخت افزاری با عملکرد بالا شرایط را برای ممکن شدن یادگیری عمیق فراهم نموده اند.
در آخر، ساختار شبکه نقش خود را در پیشرفت یادگیری عمیق ایفا میکند. با کمک بهینه سازی مداوم الگوریتم های یادگیری عمیق، تشخیص سوژه ی بهتری صورت میگیرد. برای کاربری های پیچیده تری چون تشخیص چهره و یا در سناریوهایی با نورپردازی، زوایا، حالت ها و عوامل متفاوت دیگر، ساختار شبکه دقت تشخیص را تحت تاثیر قرار خواهد داد.

موارد بکارگیری محصولات یادگیری عمیق
در دو سال گذشته، تکنولوژی یادگیری عمیق در زمینه هایی چون تشخیص صدا، بینایی رایانه ای یا کامپیوتر، ترجمه صوتی و بسیاری موارد دیگر به خوبی ظاهر شده است. این تکنولوژی در زمینه هایی چون تایید چهره و طبقه بندی تصاویر از قابلیت های انسانی نیز پیشی گرفته است؛ از این رو برای صنعت امنیت در زمینه هایی چون نظارت ویدئویی که کاربری هایی چون تشخیص چهره، تشخیص خودرو، تشخیص ویژگی بدن انسانی، دنباله روی چندین سوژه مختلف و سایر موارد را شامل میشود، به یادگیری عمیق توجه زیادی میشود.
این نوع از عملکردهای هوشمند به یک سری دوربین های نظارتی جلویی، سرورهای پشتی و دیگر محصولاتی نیازمندند که از الگوریتم های یادگیری عمیق پشتیبانی کنند. در کاربردهای با مقیاس کوچک، دوربین های جلویی میتوانند مستقیما کار استخراج ویژگی از یک انسان ساختارمند و وسیله نقلیه را انجام دهند و هزاران تصویر از چهره ی افراد را میتوان در دستگاه های جلویی ذخیره سازی کرد تا چهره ها به صورت مستقیم با یکدیگر مقایسه شوند و بدین شکل هزینه های برقراری ارتباط با سرور کاهش یابد. در کاربردهای با مقیاس بزرگ، دوربین های جلویی میتوانند با سرورهای پشتی کار کنند. مخصوصا اینکه کار ویدئویی ساختارمند به وسیله ی دستگاه های جلویی صورت میگیرد و بدینوسیله بار کاری دستگاه های پشتی کاهش می یابد؛ همچنین کارآمدی تطابق و جستجوی سرورهای پشتی ارتقاء پیدا میکند.

یادگیری عمیق سطح بعدی پیشرفت هوش مصنوعی است. این تکنولوژی بسیار فراتر از یادگیری ماشین عمل میکند؛ در یادگیری ماشین، کار طبقه بندی نظارت شده ی ویژگی ها و الگوها با کمک الگوریتم ها صورت میگیرد. دقت بهبودیافته نتیجه ی یادگیری چندلایه ای و جمع آوری گسترده داده ها است. بکارگیری این الگوریتم در تشخیص چهره، تشخیص وسیله نقلیه، تشخیص افراد و سایر پلتفرم ها باعث پیشرفت قابل توجه عملکرد آنالیتیک ها خواهد شد.
منبع: مجله a&s