



























































Deep learning is one of the only methods by which we can overcome the challenges of feature extraction. This is because deep learning models are capable of learning to focus on the right features by themselves, requiring little guidance from the programmer. Basically, deep learning mimics the way our brain functions i.e. it learns from experience. As you know, our brain is made up of billions of neurons that allows us to do amazing things. Even the brain of a one year old kid can solve complex problems which are very difficult to solve even using super-computers. For example:
- Recognize the face of their parents and different objects as well.
- Discriminate different voices and can even recognize a particular person based on his/her voice.
- Draw inference from facial gestures of other persons and many more.
Actually, our brain has sub-consciously trained itself to do such things over the years. Now, the question comes, how deep learning mimics the functionality of a brain? Well, deep learning uses the concept of artificial neurons that functions in a similar manner as the biological neurons present in our brain. Therefore, we can say that Deep Learning is a subfield of machine learning concerned with algorithms inspired by the structure and function of the brain called artificial neural networks.
Now, let us take an example to understand it. Suppose we want to make a system that can recognize faces of different people in an image. If we solve this as a typical machine learning problem, we will define facial features such as eyes, nose, ears etc. and then, the system will identify which features are more important for which person on its own.
Now, deep learning takes this one step ahead. Deep learning automatically finds out the features which are important for classification because of deep neural networks, whereas in case of Machine Learning we had to manually define these features.
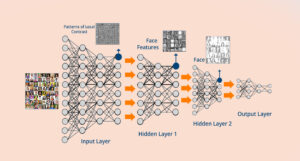
Face Recognition using Deep Networks
As shown in the image above Deep Learning works as follows:
- At the lowest level, network fixates on patterns of local contrast as important.
- The following layer is then able to use those patterns of local contrast to fixate on things that resemble eyes, noses, and mouths
- Finally, the top layer is able to apply those facial features to face templates.
- A deep neural network is capable of composing more and more complex features in each of its successive layers.
Have you ever wondered how Facebook automatically labels or tags all the person present in an image uploaded by you? Well, Facebook uses Deep Learning in a similar fashion as stated in the above example. Now, you would have realized the capability of Deep Learning and how it can outperform Machine Learning in those cases where we have very little idea about all the features that can affect the outcome. Therefore, Deep network can overcome the drawback of Machine Learning by drawing inferences from data set consisting of input data without proper labeling.

What is Neural Network?
Deep learning, as the name suggests, is a sub sect of machine learning. Deep Learning mostly involves using deep artificial neural networks (algorithms/computational models loosely inspired by the human brain) to tackle machine learning problems.
So, what is a neural network? Here’s an analogy: imagine a neural network as a series of doors one after another and think of yourself as the ‘input’ to the neural network.
Every time you open a door, you become a different person (i.e. you change in some way). By the time you open the last door, you have become a very different person. When you exit through the last door, you become the ‘output’ of the neural network. Each door, in this case, represents a layer. A neural network, therefore, is a collection of layers that transform the input in some way to produce an output. Each layer in the neural network consists of ‘weights’ and ‘biases’ — these are just numbers that augment the input.
The overall idea of a neural network is that it takes in some input (usually a collection of numbers that represent something, e.g. Red-Green-Blue values of pixels in an image), applies some mathematical transformations to the input using the weights and biases in its layers and eventually spits out an output. If you’ve taken some linear algebra class before, you can look at the input, output and weights as matrices. The input matrix gets transformed by a series of matrices (i.e. the weight and bias matrices of the layers) and that becomes your output. Of course, this is a very simplified description of how a neural network works but you get the idea (I hope).

A deep neural network is just a neural network with many layers (as you stack layers on top of another, the neural network keeps getting ‘deeper’). The basic idea of deep learning is using neural networks with multiple layers.
Now, the question is: how does a neural network learn? Backpropagation! It is a common method of training a neural net in which the initial system output is compared to the desired output, and the system is adjusted until the difference between the two is minimized. As I said before, neural networks consist of layers that consist of weights and biases (which are just collections of numbers). During the training phase, the neural network tries to find the right weights/biases that lead to the most accurate output. It does so using a method called backpropagation. Before a neural network is trained, the weights/biases are initialized, either randomly or from a previously trained model. Either ways, when training happens, the neural network changes those weights and biases based on what it ‘learns’. When we build a neural network, we have to decide on (i.e. choose or design) something called a cost function.
The cost function is basically just a mathematical function that takes in the output from a neural network (for a given input) and the ground truth data (i.e. the expected output from the neural network for that given input) and calculates how off/bad the result from the neural network was. Using optimization techniques like gradient descent, the computer calculates how to change the weights and biases such that the cost function is minimized. It keeps doing this as it trains on more and more data (get the output from the neural network, calculate cost and backpropagate to change weights). Over time, the weights and biases adjust with the data and (hopefully) you end up with a neural network that has a high output accuracy. Remember, the practical effectiveness or accuracy of a neural network is largely dependent on the data used to train it; so it’s very important that the proper dataset is built or chosen. Without good data (and a good amount of data) it can be very hard to train an accurate neural network.
PS: The cost function basically measures how inaccurate the neural network is; as we minimize the cost function by changing weights/biases, we are essentially trying to make the neural network mathematically more accurate (as defined by the cost function). However, that accuracy is dependent on the data it’s trained on; so a low cost does not necessarily mean the neural network is adequately trained.
Applications of Deep Learning
1. Speech Recognition

All of you would have heard about Siri, which is Apple’s voice controlled intelligent assistant. like other big giants, Apple has also started investing on Deep Learning to make its service better than ever.
In the area of speech recognition and voice controlled intelligent assistant like Siri, one can develop more accurate acoustic model using a deep neural network and is currently one of the most active fields for deep learning implementation. In simple words, you can build such system that can learn new features or adapt itself according to you and therefore, provide better assistance by predicting all possibilities beforehand.
2. Automatic Machine Translation
![]()
We all know that Google can instantly translate between 100 different human languages, that too very quickly as if by magic. The technology behind Google Translate is called Machine Translation and has been savior for people who can’t communicate with each other because of the difference in the speaking language. Now, you would be thinking that this feature has been there for a long time, so, what’s new in this? Let me tell you that over the past two years, with the help of deep learning, Google has totally reformed the approach to machine translation in its Google Translate. In fact, deep learning researchers who know almost nothing about language translation are putting forward relatively simple machine learning solutions that are beating the best expert-built language translation systems in the world. Text translation can be performed without any pre-processing of the sequence, allowing the algorithm to learn the dependencies between words and their mapping to a new language. Stacked networks of large recurrent neural networks are used to perform this translation.
3. Instant Visual Translation

As you know, deep learning is used to identify images that have letters and where the letters are on the scene. Once identified, they can be turned into text, translated and the image recreated with the translated text. This is often called instant visual translation.
Now, imagine a situation where you have visited any other country whose native language is not known to you. Well, no need to worry, using various apps like Google Translate you can go ahead and perform instant visual translations to read signs or shop boards written in another language. This has been possible only because of Deep Learning.
4. Behavior: Automated Self Driven Cars

Google is trying to take their self-driving car initiative, known as WAYMO, to a whole new level of perfection using Deep Learning. Therefore, rather than using old hand-coded algorithms, they can now program system that can learn by themselves using data provided by different sensors. Deep learning is now the best approach to most perception tasks, as well as to many low-level control tasks. Hence, now even people who do not know to drive or are disabled, can go ahead and take the ride without depending on anyone else.
Here, I have only mentioned few famous real-life use cases where Deep Learning is being used extensively and showing promising results. There are many other applications of deep learning along with many fields which is yet to be explored.
Source: edureka & towardsdatascience




